Rachunek prawdopodobieństwa i statystyka
Piotr Śmiałek
Poniższy dokument zawiera analizę dystrybucji zwrotów (DoR), która jest istotna dla podejmowania decyzji inwestycyjnych, oceny ryzyka, i budowania bardziej precyzyjnych modeli prognoz finansowych .
Distribution of Returns wykonałem dla Microsoft Corporation – amerykańskie przedsiębiorstwo informatyczne. Najbardziej znane jako producent systemów operacyjnych MS-DOS, Microsoft Windows i oprogramowania biurowego Microsoft Office. Na rynku od 1986 roku.
Do pobrania danych finansowych wykorzystam API yfinance, która umożliwi mi pobieranie historycznych danych instrumentów finansowych z yahoofinance Wiecej informacji: https://pypi.org/project/yfinance/
!pip install yfinance
Importowanie niezbędnych bibliotek
import yfinance as yf
import sqlite3
import numpy as np
import pandas as pd
import matplotlib as mplt
from sklearn.linear_model import LinearRegression as linreg
from sklearn.preprocessing import PolynomialFeatures as polyfeat
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
from tabulate import tabulate
%matplotlib inline
from IPython.display import display, HTML
display(HTML('<style>.container {width: 50% !important}</style>'))
Importowanie danych
Do importowania danych z bazy użyję funkcji:
def import_data(symbol, database_name, data_intervals):
data = yf.download(symbol, period="max", interval=data_intervals)
conn = sqlite3.connect("./data/" + database_name)
data.to_sql(name=symbol, con=conn , if_exists="replace", index=True)
conn.close()
Za pomocą powyższej funkcji bedę mógł stworzyć osobne zbiory danych dla podanego instrumentów finansowego, dla interwałów: dniowego, tygodniowego, miesięcznego i kwartalnego.
import_data("MSFT", "microsoft_daily.db", "1d")
import_data("MSFT", "microsoft_weekly.db", "1wk")
import_data("MSFT", "microsoft_monthly.db", "1mo")
import_data("MSFT", "microsoft_quarterly.db", "3mo")
Poniższa funkcja umożliwi mi pracę z danymi za pomocą bibioteki pandas, które na razie są zapisane w bazie SQLite.
def convert_to_dataframe(symbol,database_path):
conn = sqlite3.connect(database_path)
query = f"SELECT * FROM {symbol}"
df = pd.read_sql(query, conn)
conn.close()
return df
Konwersja danych do DataFrame
df_microsoft_daily = convert_to_dataframe("MSFT", "./data/microsoft_daily.db")
df_microsoft_weekly = convert_to_dataframe("MSFT", "./data/microsoft_weekly.db")
df_microsoft_monthly = convert_to_dataframe("MSFT", "./data/microsoft_monthly.db")
df_microsoft_quarterly = convert_to_dataframe("MSFT", "./data/microsoft_quarterly.db")
Wykres cenowy dla MSFT wygląda następująco:
df_microsoft_daily['Date'] = pd.to_datetime(df_microsoft_daily['Date'])
df_microsoft_daily.set_index('Date', inplace=True)
plt.figure(figsize=(15, 5))
plt.plot(df_microsoft_daily.index, df_microsoft_daily['Close'], label='Cena zamknięcia', color='blue')
plt.title('Microsoft Corporation (MSFT)')
plt.xlabel('Time')
plt.ylabel('Price in $')
plt.legend()
plt.grid(True)
plt.show()

Każda z wczytanych tabel posiada 7 kolumn:
Date
Open - otwarcie to cena instrumentu finansowego (takiego jak akcje) w momencie otwarcia sesji handlowej na rynku. Oznacza to, ile jednostek waluty trzeba było zapłacić lub otrzymać w zamian za jednostkę instrumentu finansowego napoczątku sesji.
High - najwyższa cena instrumentu finansowego osiągnięta w trakcie danego okresu czasu (np. jednej sesji handlowej). To jest największa wartość, którą osiągnęła cena w danym przedziale czasowym.
Low - najniższa cena instrumentu finansowego osiągnięta w trakcie danego okresu czasu. To jest najmniejsza wartość, którą osiągnęła cena w danym przedziale czasowym.
Close - cena instrumentu finansowego w momencie zamknięcia sesji handlowej. Oznacza to, ile jednostek waluty trzeba było zapłacić lub otrzymać w zamian za jednostkę instrumentu finansowego na końcu sesji.
Adj Close - cena instrumentu finansowego w momencie zamknięcia sesji handlowej. Oznacza to, ile jednostek waluty trzeba było zapłacić lub otrzymać w zamian za jednostkę instrumentu finansowego na końcu sesji. Jest zmodyfikowaną ceną zamknięcia, która uwzględnia różne korekty i dostosowania, takie jak dywidendy, podziały akcji i zdarzenia korporacyjne.
Volume - wolumen to liczba jednostek instrumentu finansowego, które zostały wymienione w danym okresie czasu. Oznacza to, ile razy dany instrument finansowy został kupiony lub sprzedany w danym przedziale czasowym.
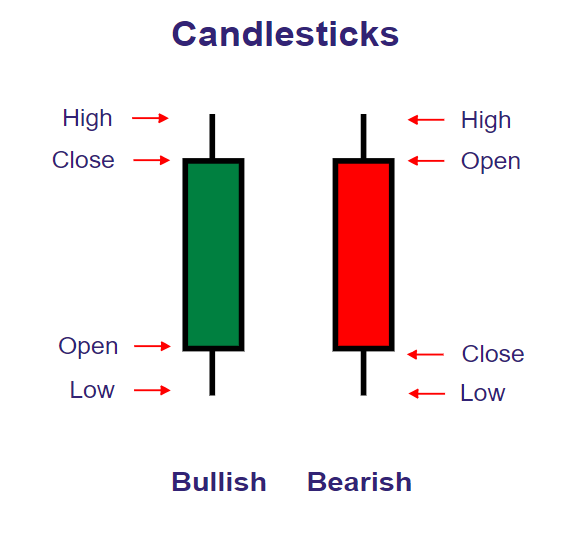
Najłatwiej interpretuje się te kolumny, kiedy wiemy co to wykres świecowy, z którym można się zetknąć analizując czy przeglądając wykresy instrumentów finansowych. Jedna 'świeczka' reprezentuje jakiś interwał, w którym jest przedstawiony wykres np. jedna świeczka reprezentuje jeden dzień dla interwału 1dniowego, miesiąc dla interwału miesięcznego. Czerwona świeca oznacza, że cena otwarcia dla danego interwału jest wyższa niż cena zamknięcia dla danego interwału. Mówiąc prościej czerwona świeca oznacza ze cena sprade ceny w danym interwale, jest dokładnie odwrotnie dla zielonej świecy. 'Wąsy' świeczek oznaczają poziomy cenowe w jakich cena oscylowała dla danego interwału, końce tych 'wąsów' wyznaczają najwyższa i najniższa cene w danym interwale. Open i Close to ceny odpowiednio otwarcia i zamknięcia dla danego interwału.
Sprawdzenie poprawności wczytanych danych:
df_microsoft_daily.shape
df_microsoft_weekly.shape
df_microsoft_monthly.shape
df_microsoft_quarterly.shape
df_microsoft_daily.head()
df_microsoft_weekly.head()
df_microsoft_monthly.head()
df_microsoft_quarterly.head()
Podstawowe informacje o wczytanych danych:
df_microsoft_daily.info()
df_microsoft_weekly.info()
df_microsoft_monthly.info()
df_microsoft_quarterly.info()
Widać, że dane zostały wprowadzone prawidłowo. Liczba rekordów jest zgodna z oczekiwaniami. Typy danych są także zgodne z oczekiwaniami oprócz kolumny Date, w której data jest typu object, natomiast nie będziemy jej wykorzystywać do analizy.
Czyszczenie danych
Ogólne informacje o wczytanych danych
df_microsoft_daily.describe()
df_microsoft_weekly.describe()
df_microsoft_monthly.describe()
df_microsoft_quarterly.describe()
Na podstawie powyższych tabel, nie wykryłem żadnych nieprawidłowości.
Warto również sprawdzić czy w żadnej kolumnie nie brakuje wartości.
df_microsoft_daily.isnull().sum()
df_microsoft_weekly.isnull().sum()
df_microsoft_monthly.isnull().sum()
df_microsoft_quarterly.isnull().sum()
Na postawie powyższych tabel można stwierdzić, że tabele są kompletne i nie brakuje informaci w żadnej komórce stworzonych baz danych.
Do przeprowadzenia analizy DoR (Distrubution of Returns), zebrane dane nie są wystarczające. Należy uzupełnić podane tabele o trzy dodatkowe kolumny. Nie będe analizował szczegółowo każdej z nich w dalszej częsci, bo rozmiar dlugość teog projektu wzrosłaby kilkuktornie. Najważniejszą kolumną jest Close-to-Close Returns, ona jest najczęsciej spotykana przy analize i dostarczca nam najwiecej inforamcji i instrumencie finansowym.
Close-to-Close Returns [daily, weekly, monthly quarterly data] $Formula = \frac{Close_{ period [x+1]} - Close_{period [x]}}{Close_ {period [x]}} $
High-to-Low Returns [daily, weekly, monthly quarterly data] $Formula = \frac{High_{ period [x]} - Low_{period [x]}}{Low_ {period [x]}} $
Open-to-Close Returns [daily data] $Formula = \frac{Close_{ period [x]} - Open_{period [x]}}{Open_ {period [x]}} $
Poniższa funkcja realizuje powyższe formuły dla podanego data frame'u: Dla interwałów wyższych niż jednodniowy kolumna Open-to-Close Returns taraci sens, z tego powodu nie będzie ona obliczna dla interwału tygodniowego, miesięcznego i kwartalnego.
def compute_additional_columns(symbol, df, database_path, interval):
if interval == "daily":
df['Open-Close Returns'] = ((df['Close'] - df['Open']) / df['Open']) * 100
df['High-Low Returns'] = ((df['High'] - df['Low']) / df['Low']) * 100
df['Close-Close Returns'] = ((df['Adj Close'] - df['Adj Close'].shift(-1)) / df['Adj Close'].shift(-1)) * 100
conn = sqlite3.connect(database_path)
df.to_sql(name=symbol, con=conn, if_exists="replace", index=True)
conn.close()
Dodanie kolumn do tabel:
compute_additional_columns("MSFT", df_microsoft_daily, "./data/microsoft_daily.db", "daily")
compute_additional_columns("MSFT", df_microsoft_weekly, "./data/microsoft_weekly.db", "weekly")
compute_additional_columns("MSFT", df_microsoft_monthly, "./data/microsoft_monthly.db", "monthly")
compute_additional_columns("MSFT", df_microsoft_quarterly, "./data/microsoft_quarterly.db", "quarterly")
df_microsoft_daily.isnull().sum()
df_microsoft_weekly.isnull().sum()
df_microsoft_monthly.isnull().sum()
df_microsoft_quarterly.isnull().sum()
Widzimy, że we każdej z tabel jest jedna komórka w kolumnie Close-Close Returns,w której jest null. Wynika to z tego, że formuła do obliczania Close-Close Returns dla komórki w wierszu x bierze wartość z wiersza x+1, więc dla ostatniego wiersza nie będziemy mieli tej wartośći. Null w dalszej części jest uwzględniony i wypełniony zerem.
Teraz tabele wyglądają w następujący sposób:
df_microsoft_daily.head()
df_microsoft_weekly.head()
df_microsoft_monthly.head()
df_microsoft_quarterly.head()
Wartości odstające zbioru danych
W celu wyznaczenia wartości odstających, posłużymy się wykresem pudełkowym. Wszystkie wartości, które nie znajdują się między lewym i prawym wąsem, traktowane są jako wartości odstające, natomiast nie będę ich usuwał, ponieważ w analizie finansowej mogą być przedatne i dostaraczją nam dodatkowych informacji. Do wyznaczenia położenia lewego oraz prawego wąsa posłużę się poniższymi wzorami:
- lewy wąs: $max{x_{1:n}, Q_{1} - 1,5 * IQR }$
- prawy wąs: $min{x_{1:n}, Q_{3} + 1,5 * IQR }$
- $Q_{1}$ kwartyl dolny (kwartyl rzędu $\frac{1}{4}$)
- $Q_{3}$ kwartyl dolny (kwartyl rzędu $\frac{3}{4}$)
- $IQR$ - rozstęp międzykwartylowy ($IQR = Q_{3} - Q_{1}$)
fun = lambda n: f'{n:.2f}'
show_tab = lambda fn, values: print(tabulate(fn(values), []))
def outliers(data):
Q1 = data.quantile(.25)
Q3 = data.quantile(.75)
IQR = Q3 - Q1
left = Q1 - 1.5*IQR
right = Q3 + 1.5*IQR
output = [
('Kwartyl dolny Q1:', fun(Q1)),
('Kwartyl górny Q3:', fun(Q3)),
('Odstęp międzykwartylowy IQR:', fun(IQR)),
('Lewy wąs:', fun(left)),
('Prawy wąs:', fun(right))
]
return output
def outliers_in_percentage(data):
Q1 = data.quantile(.25)
Q3 = data.quantile(.75)
IQR = Q3 - Q1
left = Q1 - 1.5*IQR
right = Q3 + 1.5*IQR
left_sum = (data < left).sum()
right_sum =(data > right).sum()
data_length = data.count()
output = [
('Ilość wartości za lewym wąsem: ', fun(left_sum)),
('Ilość wartości za prawym wąsem: ', fun(right_sum)),
('Procentowa wartości poza wąsami', fun((right_sum + left_sum)*100/data_length)),
]
return output
Do rysowania wykresów wykorzystuję funkcję:
def draw_plots(df, feature):
fig, ax = plt.subplots(1, 2, figsize=(15, 5))
sns.boxplot(ax=ax[0], data=df, x=feature)
sns.histplot(ax=ax[1], data=df[feature])
sns.despine()
Analiza wartości odstających dla microsoftdaily.db
draw_plots(df_microsoft_daily, "High-Low Returns")

show_tab(outliers, df_microsoft_daily['High-Low Returns'])
show_tab(outliers_in_percentage,df_microsoft_daily['High-Low Returns'])
Naturalnie High-Low Returns moze mieć tylko wartości nieujemne, ponieważ jest to procentowy zwrot między najniższa a najwyższa cena w danym interwale. Możemy zauważyć że kwartyl dolny Q1 i górny Q3 dla Close-Close Returns wynoszą odpowiednio 1.43% i 3.15%. Wartości odstające stanowią około 4.5% danych w tabeli.
draw_plots(df_microsoft_daily, "Close-Close Returns")

show_tab(outliers,df_microsoft_daily["Close-Close Returns"] )
show_tab(outliers_in_percentage,df_microsoft_daily["Close-Close Returns"])
Możemy zauważyć że kwartyl dolny Q1 i górny Q3 dla Close-Close Returns wynosi odpowiednio -1.12% i 0.93%. Wartości odstające stanowią około 5% danych w tabeli.
draw_plots(df_microsoft_daily, "Open-Close Returns")

show_tab(outliers,df_microsoft_daily["Open-Close Returns"] )
show_tab(outliers_in_percentage,df_microsoft_daily["Open-Close Returns"])
Możemy zauważyć że kwartyl dolny Q1 i górny Q3 dla Close-Close Returns wynosi odpowiednio -0.86% i 0.99%. Wartości odstające stanowią około 5% danych w tabeli.
draw_plots(df_microsoft_daily,'Volume')

show_tab(outliers, df_microsoft_daily['Volume'])
show_tab(outliers_in_percentage,df_microsoft_daily['Volume'])
Wartości odstające dla każdej z kolumn oscylują wokół 5%. W przypadku analizy finansowej nie chcemy się ich pozbywać, ponieważ moga one mieć istotny wpływ na wynik końcowy analizy.
Szczegółowa analiza wybranych cech tabel microsoft_daily.db
Wyznaczanie współczynników W celu wyznaczenia odpowiednich współczynników, możemy skorzystać z poniższych wzorów.
Wartość średnia: $m = E(X) = \sum p_k * x(k)$
Wariancja: $Var(X) = E((X - m)^2)$
Moment rzędu k: $m_k = E(X^k)$
Moment centralny rzędu k: $\mu_k = E((X-m)^k)$
Odchylenie strandardowe $\sigma = \sqrt{Var(X)}$
Odchylenie przeciętne $d_1 = E|X-m|$
Kurtoza $K = Kurt(X) = \frac{\mu_4}{\sigma_4}$
Wspołczynnik asymetrii - skośności $A = \gamma_1 = \frac{\mu_3}{\sigma_3}$
Współczynnik wyostrzenia $\gamma_2 = Kurt(X)-3$
Nie będę natomiast korzystał z tych wzorów ponieważ, powyższe współczynniki można obliczyć przez wbudowane metody i funkcjew w bibliotekach numpy i scipy
Funckje pomocnicze
Funckja, która pomoże wyznaczyć wskaźniki położenia:
def pos_indicators(values):
min_ = values.min()
max_ = values.max()
Q1 = values.quantile(.25)
Q3 = values.quantile(.75)
output = [
('Najmniejsza wartość (min)', fun(min_)),
('Największa wartość (max)', fun(max_)),
('Średnia arytmetyczna', fun(values.mean())),
('Kwantyl pierwszy (Q1)', fun(Q1)),
('Mediana (Q2)', fun(values.median())),
('Kwantyl trzeci (Q3)', fun(Q3)),
]
return output
Funkcja, która pozwoli obliczyć wskaźniki rozproszenia:
def scatter_indicators(values):
std = values.std()
min_ = values.min()
max_ = values.max()
Q1 = values.quantile(.25)
Q3 = values.quantile(.75)
IQR = Q3 - Q1
Q = IQR / 2
skewness = round(stats.skew(values), 2)
skew_msg = 'prawostronnie skośny' if skewness > 0 else 'lewostronnie skośny' if skewness < 0 else 'symetryczny'
excess_kurtosis = stats.kurtosis(values)
kurtosis = excess_kurtosis + 3
kurtosis_msg = 'leptokurtyczny' if excess_kurtosis > 0 else 'platykurtyczny' if excess_kurtosis < 0 else 'mezokurtyczny'
return [
('Odchylenie standardowe', fun(std)),
('Wariancja', fun(std ** 2)),
('Rozstęp między skrajnymi wartościami (max - min)', fun(max_ - min_)),
('Rozstęp międzykwartylowy (IQR)', fun(IQR)),
('Odchylenie ćwiartkowe', fun(Q)),
('Współczynnik asymetrii (skośności)', f"{fun(skewness)} ({skew_msg})"),
('Kurtoza', fun(kurtosis)),
('Współczynnik wyostrzenia', f'{fun(excess_kurtosis)} ({kurtosis_msg})')
]
Dodatkowe statystyki:
def additional_statistics(df):
all_values = df.count()
positive_values = (df > 0).sum()
positive_values_probability = positive_values * 100/ all_values
avg_positive_return = df[df > 0].mean()
negative_values = (df < 0).sum()
negative_values_probability = negative_values * 100/ all_values
avg_negative_return = df[df < 0].mean()
zero_values = (df == 0).sum()
zero_values_probability = zero_values * 100/ all_values
return [
('Liczba wartości pozytywnych:', fun(positive_values)),
('Liczba wartosci negatywnych:', fun(negative_values)),
('Liczba wystepowania zer:', fun(zero_values)),
('Procent dodatnich wartości:', fun(positive_values_probability)),
('Procent negatywych wartosci:', fun(negative_values_probability)),
('Procent wystepowania zer:', fun(zero_values_probability)),
('Średni pozytywny zwrot: ', fun(avg_positive_return)),
('Średni negatywny zwrot: ', fun(avg_negative_return)),
]
def compute_intervals_probability(df, no_bins):
return df.value_counts(normalize=True, bins=no_bins, sort=False)
def compute_cumulative_intervals_probability(intervals_probability):
return intervals_probability.cumsum()
def count_frequency_intervals(df, no_bins):
intervals = pd.cut(df, bins=no_bins, include_lowest=True)
counter = intervals.value_counts(sort=False)
return counter
Funkcja, która rysuje wykres kołowy, mówiący o tym jaka część zwrotów jest pozytywna a jaka negatywna.
def plot_pie_chart(df):
positive = (df > 0).sum()
negative = (df < 0).sum()
zero = (df == 0).sum()
plt.figure(figsize=(15,6.5))
labels = ['Pozytywne', 'Negatywne', 'Zera']
sizes = [positive, negative, zero]
colors = ['green', 'red', 'blue']
plt.pie(sizes, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
plt.title('Rozkład procentowy wartości pozytywnych, negatywnych i zer')
plt.axis('equal')
plt.show()
Funckja, która tworzy wykres przedstawiający rozkład danych.Na wykresie naniesone są także linie pionowe, które informują o tym, w którym miejscu znajdują się mediana i odchylenia standardowe.
def distribution_chart(df_data, statistic_data, no_bins):
g = sns.displot(data=df_data, kde=True, bins=no_bins)
g.fig.set_figwidth(15)
g.fig.set_figheight(6.5)
plt.axvline(statistic_data.median(), color='red', linestyle='dashed', linewidth=2, label='Średnia')
plt.axvline(statistic_data.median(), color='green', linestyle='dashed', linewidth=2, label='Mediana')
plt.axvline(statistic_data.median() + df_data.std(), color='orange', linestyle='dashed', linewidth=1, label='Średnia + 1SD')
plt.axvline(statistic_data.median() - df_data.std(), color='orange', linestyle='dashed', linewidth=1, label='Średnia - 1SD')
plt.axvline(statistic_data.median() + 2*df_data.std(), color='blue', linestyle='dashed', linewidth=1, label='Średnia + 2SD')
plt.axvline(statistic_data.median() - 2*df_data.std(), color='blue', linestyle='dashed', linewidth=1, label='Średnia - 2SD')
plt.legend()
return g
Funkcja tworzy wykres, na którym porównywane są gęstości jądrowe rzeczywistych danych (oznaczonych kolorem niebieskim) i danych symulowanych z rozkładu normalnego (oznaczonych kolorem pomarańczowym)
def compare_with_normal_distribution(real_data):
mean = real_data.mean()
std = real_data.std()
simulated_data = np.random.normal(mean, std, size=1000000)
plt.figure(figsize=(15,6.5))
# Rysowanie wykresu
sns.kdeplot(real_data, label='Real Data', color='blue')
sns.kdeplot(simulated_data, label='Simulated Data', color='orange')
# Dodawanie tytułów i etykiet osi
plt.title('Porównanie Rozkładu Normalnego i Rzeczywistych Danych')
plt.xlabel('Wartości')
plt.ylabel('Gęstość')
# Dodawanie legendy
plt.legend()
plt.show()
distribution_chart(df_microsoft_daily['Close-Close Returns'],df_microsoft_daily['Close-Close Returns'],50)

Wykres dla wszystkich danych bez filtracji jest mało czytelny. Widać że wartość średnia oscyluje wokół zera.
compare_with_normal_distribution(df_microsoft_daily['Close-Close Returns'])

Z powrównania wykresów gęstości rozkładu normalnego i rzeczyswistych danych, możemy stwierdzić,ze kurtoza jest dodatnia, czyli rozkład jest leptokurtyczny.
data = df_microsoft_daily['Close-Close Returns']
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left i right
selected_values = data[(data >= left) & (data <= right)]
distribution_chart(selected_values, df_microsoft_daily['Close-Close Returns'],20 )

Ten wykres jest już dużo bardziej czytelny za sprawą odfiltorwania wartości odstających, które uniemożliwiały odczytanie wartości z wykresu.
df_microsoft_daily['Close-Close Returns'] = df_microsoft_daily['Close-Close Returns'].fillna(0)
show_tab(pos_indicators,df_microsoft_daily['Close-Close Returns'])
show_tab(scatter_indicators, df_microsoft_daily['Close-Close Returns'])
Szczegółowe obliczenie wskaźników rozproszenia potwierdza nasze prezczucia formułowane na podstawie wyglądu wykresu. Rozkład ma chakarkter mocno leptokurtyczny, bo współczynnik wyostrzenia (względem rozkłądu normalnego) to az 23.88. Rozkłaad jest prawostronnie skośny co oznacza, że 'ogon' znajduje się po prawej stronie wykresu.
intervals_prob = compute_intervals_probability(df_microsoft_daily['Close-Close Returns'],20)
intervals_prob
Tabela przedstawia prawdopodobieństwo występowania danych w podanych przedziałach. W przedziale od -1.5% do 1.5% znajduje się aż 64% danych.
compute_cumulative_intervals_probability(intervals_prob)
Tabela przedstawia skumulowane pradopodobieństwo dla przedziałow. Prawdopodobieństwo skumulowane gwałtownie rośnie dla przedziału -1.5%, 1,5%.
Dystrybuantę tworzę za pomocą funckji:
# Rysujemy dystrybuantę
def distribuant(data):
plt.figure(figsize=(15,6.5))
sns.ecdfplot(data)
# Dodajemy tytuł i opis osi
plt.title('Dystrybuanta')
plt.xlabel('Procentowe wartosci zwrotów')
plt.ylabel('Prawdopodobieństwo kumulatywne')
plt.show()
Dystrybuanta empiryczna:
distribuant(df_microsoft_daily['Close-Close Returns'])

count_frequency_intervals(df_microsoft_daily['Close-Close Returns'],20)
Tabela przedstawia ilość wystąpień zmiennej loswowej w danych przedziałach. Najwiecej danych jest pomiedzy 1.5% a -1.5%
show_tab(additional_statistics,df_microsoft_daily['Close-Close Returns'])
plot_pie_chart(df_microsoft_daily['Close-Close Returns'])

Liczba negatywnych wartości jest delikatnie większa od pozytywnych.
Analiza wartości odstających dla microsoft_weekly.db
draw_plots(df_microsoft_weekly, "High-Low Returns")

show_tab(outliers, df_microsoft_weekly['High-Low Returns'])
show_tab(outliers_in_percentage,df_microsoft_weekly['High-Low Returns'])
Kwartyl dolny i kwartyl dolny wynoszą odpowiednio 3.68% i 8.01% Bez zaskoczenia dla interwału tygodniowego zmienność jest dużo większa niż dla interwału 1dniowego. Około 4% wartości leży poza lewym lub prawym wąsem.
draw_plots(df_microsoft_weekly, "Close-Close Returns")

show_tab(outliers, df_microsoft_weekly['Close-Close Returns'])
show_tab(outliers_in_percentage,df_microsoft_weekly['Close-Close Returns'])
Poza wąsami leży podobnie jak w interwale 1dniowym około 5% wartości, natomiast zmienność rośnie dużo wolniej. Kwartyl dolny Q1 i kwartylgórny Q3 wynoszą odpowiednio -2.69% i 1.85% co nie odbiega bardzo od interwału 1dniowego gdzie oberwowaliśmy około +-1.5%.
draw_plots(df_microsoft_weekly,'Volume')

show_tab(outliers, df_microsoft_weekly['Volume'])
show_tab(outliers_in_percentage,df_microsoft_weekly['Volume'])
Analiza szczegółowa microsoft_weekly.db
distribution_chart(df_microsoft_weekly['Close-Close Returns'],df_microsoft_weekly['Close-Close Returns'],40)

compare_with_normal_distribution(df_microsoft_weekly['Close-Close Returns'])

Wizualnie wydaje się, że współczynnik wyostrzenia jest mniejszy dla interwału tygodniowego niż dla inetrwału 1dniowego.
data = df_microsoft_weekly['Close-Close Returns']
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
distribution_chart(selected_values, df_microsoft_weekly['Close-Close Returns'],20 )

Wykres dystrybucji po odfiltrowaniu wartości odstających.
df_microsoft_weekly['Close-Close Returns'] = df_microsoft_weekly['Close-Close Returns'].fillna(0)
show_tab(pos_indicators,df_microsoft_weekly['Close-Close Returns'])
show_tab(scatter_indicators, df_microsoft_weekly['Close-Close Returns'])
Interwał tygodniowy ma kurtozę bardziej znormalizowaną - jest mniej wyostrzona, tak jak założyłem na podstawie obserwacji wykresu, co nie zmienia faktu, że rozkład dalej ma charakter leptokurtyczny i tak samo jak dla interwału 1dniowego rozkłąd jest prawostronnie skośny, czyli ma ogon po prawej stronie wykresu.
intervals_prob = compute_intervals_probability(df_microsoft_weekly['Close-Close Returns'],15)
intervals_prob
Tabela przedstawiwa prawdopodobieństwo wystepowania zmiennej losowej dla danych przedziałwo. W przedziale -4.5% do 2.5%, leży aż 65% danych.
compute_cumulative_intervals_probability(intervals_prob)
Dystrybuanta empiryczna:
distribuant(df_microsoft_weekly['Close-Close Returns'])

Dystrybuanta jest mniej wyostrzona niż to było w przypadku interwału 1dniowego - prawdopodobieństwo kumulatywne rośnie wolniej.
show_tab(additional_statistics,df_microsoft_weekly['Close-Close Returns'])
plot_pie_chart(df_microsoft_weekly['Close-Close Returns'])

Warto zauważyć, że dla interwału tygodnioewgo zwiększyła się ilość negatywnych zwrotów i wynosi ona około 55% wszystkich zmiennych losowych.
analiza wartości odstajacych microsoft_monthly.db
draw_plots(df_microsoft_monthly, "High-Low Returns")

show_tab(outliers, df_microsoft_monthly['High-Low Returns'])
show_tab(outliers_in_percentage,df_microsoft_monthly['High-Low Returns'])
draw_plots(df_microsoft_monthly, "Close-Close Returns")

show_tab(outliers, df_microsoft_monthly['Close-Close Returns'])
show_tab(outliers_in_percentage,df_microsoft_monthly['Close-Close Returns'])
draw_plots(df_microsoft_monthly, "Volume")

show_tab(outliers, df_microsoft_monthly['Volume'])
show_tab(outliers_in_percentage, df_microsoft_monthly['Volume'])
Szczegółowa analiza wybranych cech tabeli microsoft_monthly.db
distribution_chart(df_microsoft_monthly['Close-Close Returns'],df_microsoft_monthly['Close-Close Returns'],40)

compare_with_normal_distribution(df_microsoft_monthly['Close-Close Returns'])

Wizualnie możemy stwierdzić, że rozkład zmiennej jest 'przesuniety w lewo' względem wygenerowanego rozkładu normalnego.
data = df_microsoft_monthly['Close-Close Returns']
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
distribution_chart(selected_values, df_microsoft_monthly['Close-Close Returns'],20 )

Rozkład dystrybucji z odfiltrowanymi wartościami odstającymi.
df_microsoft_monthly['Close-Close Returns'] = df_microsoft_monthly['Close-Close Returns'].fillna(0)
show_tab(pos_indicators,df_microsoft_monthly['Close-Close Returns'])
show_tab(scatter_indicators, df_microsoft_monthly['Close-Close Returns'])
Rozkład dalej ma charakter lepotkurtyczny i jest prawostronnie skońny. To co jest warte zauważenia to, ze dla interwału miesięcznego mediana i wartość średnia, są ujemne i wynoszą odpowiednio -2.18% i -1.47%. Dla niższych interwałów te wartości oscylowały w granichac zera.
intervals_prob = compute_intervals_probability(df_microsoft_monthly['Close-Close Returns'],15)
intervals_prob
Tabela przedstawia prawdopodobieństwo wystąpienia zmiennej losowej w danym przedziale. Co warte odnotowania ponad połowa wszystkich wartości najduje się pomiedzy -11% a 0.5%
compute_cumulative_intervals_probability(intervals_prob)
Tabela przedstawia prawdopodobieństwo kumulatywne dla danych przdziałow
distribuant(df_microsoft_monthly['Close-Close Returns'])

count_frequency_intervals(df_microsoft_monthly['Close-Close Returns'],20)
show_tab(additional_statistics,df_microsoft_monthly['Close-Close Returns'])
plot_pie_chart(df_microsoft_monthly['Close-Close Returns'])

Powyższy wykres jest tylko potwierdzeniem trendu, że wraz ze wzrostem interwału rośnie ilość wartości które są mniejsze ujemne. W przypadku interwału miesięcznego aż 61% wartości jest ujemna.
Analiza wartości odstających dla microsoft_quarterly.db
draw_plots(df_microsoft_quarterly, "High-Low Returns")

show_tab(outliers, df_microsoft_quarterly['High-Low Returns'])
Dla tak dużego interwału ogromne są też wachania cenowe instrumentu finansowego. Q1 wynosi 17.33% a Q3 az 34.84%.
show_tab(outliers_in_percentage, df_microsoft_quarterly['High-Low Returns'])
draw_plots(df_microsoft_quarterly, "Close-Close Returns")

show_tab(outliers, df_microsoft_quarterly['Close-Close Returns'])
distribution_chart(df_microsoft_quarterly['Close-Close Returns'],df_microsoft_quarterly['Close-Close Returns'],20)

Mediana dla tak dużego interwału jest jeszcze bardziej 'na lewo' od zera. Odhylenie średnie wynoski dwadzieścia kilka procent.
compare_with_normal_distribution(df_microsoft_quarterly['Close-Close Returns'])

Rozkład empiryczny jest jeszcze widocznie mniej wyostrzony niż rozkład dla mniejszych interwałów.
data = df_microsoft_quarterly['Close-Close Returns']
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
distribution_chart(selected_values, selected_values,25 )

Rozkład dla odfiltrowanych wartości odstających.
df_microsoft_quarterly['Close-Close Returns'] = df_microsoft_quarterly['Close-Close Returns'].fillna(0)
show_tab(pos_indicators,df_microsoft_quarterly['Close-Close Returns'])
show_tab(scatter_indicators, df_microsoft_quarterly['Close-Close Returns'])
Charakter wykresu nie zmienia sie, dalej jest leptokurtyczny, jednak współczynnik wyostrzeniwynosi tylko 0.91, to niewiele w porównaniu dla współczynnika dla interwału 1dniowego, gdize wynosił on około 23. Odchylenie standardowe wynosi 13% .
intervals_prob = compute_intervals_probability(df_microsoft_quarterly['Close-Close Returns'],10)
intervals_prob
Prawie połowa danych leży pomiedzy -8.5% a 8.5%
compute_cumulative_intervals_probability(intervals_prob)
distribuant(df_microsoft_quarterly['Close-Close Returns'])

Dystrubuanta empiryczna z racji niewielkiej liczby danych jest bardziej skokowa, porównując z niższymi interwałami.
count_frequency_intervals(df_microsoft_quarterly['Close-Close Returns'],10)
show_tab(additional_statistics,df_microsoft_quarterly['Close-Close Returns'])
plot_pie_chart(df_microsoft_quarterly['Close-Close Returns'])

Wykres potwierdza nasze przypuszczenia z początku analizy szczegółowej interwałów. Wraz ze wzrostem interwału rośnie prawdopodobieństwo, że zwrot będzie miał wartość ujemną. Tylko 1/3 wszystkich wartości jest dodatnia.
Testy statystyczne
W tej sekcji przeprowadziłem kilka testów statystycznych, które głownie sprawdzały zbieżność do rozkładu normalnego. Testy zostały wykonane dla kolumnty Close-Close Returns
Test D'Agostino-Pearsona
Test normalności D'Agostino-Pearsona to statystyczny test używany do oceny, czy próbka danych pochodzi z rozkładu normalnego. Test ten bazuje na trzecim i czwartym momentach statystyki, czyli na kurtozie i skośności. Statystyka testowa ma postać: $K^2 = Z^2_{A} +Z^2_{K}$
gdzie: $\ Z^2_{A}$ : statystyka testowa testu skośności $\ Z^2_{K}$ : statystyka testowa testu kurtozy.
$H_{0}$ - próbka pochodzi z rozkładu normalnego $H_{1}$ - próbka nie pochodzi z rozkładu normalnego
Za hipotezę zerową uznajemy $H_{0}$ - próbka pochodzi z rozkładu normalnego natomiast hipotezą alternatywna jest $H_{1}$
Mała wartość $p$ (zazwyczaj mniejsza niż 0,05) oznacza odrzucenie hipotezy zerowej, co sugeruje, że dane nie pochodzą z rozkładu normalnego. Wartość p większa niż 0,05 nie dostarcza wystarczających dowodów na odrzucenie hipotezy zerowej, co sugeruje, że dane mogą pochodzić z rozkładu normalnego.
column = 'Close-Close Returns'
interval = '1day interval'
stat, p = stats.normaltest(df_microsoft_daily[column])
print(interval + " for " +column + " -> ""p_value: ", p)
p_value jest tak małe dla kolumny 'Close-Close Returns' na interwale 1dniowym, że wykonanie testu statystycznego zwraca 0 dla p. Oznacza to odrzucenie hipotezy zerowej i przyjumjemy, że próbka nie pochodzi z rozkładu normalnego.
column = 'Close-Close Returns'
interval = '1week interval'
stat, p = stats.normaltest(df_microsoft_weekly[column])
print(interval + " for " +column + " -> ""p_value: ", p)
Dla interwału tygodniowego dalej p < 0.05 co oznacza odrzucenie hipotezy zerowej i uznanie, że próbka nie pochodzi z rozkładu normalnego.
column = 'Close-Close Returns'
interval = '1month interval'
stat, p = stats.normaltest(df_microsoft_monthly[column])
print(interval + " for " +column + " -> ""p_value: ", p)
Dla interwału miesiecznego p < 0.05 co oznacza odrzucenie hipotezy zerowej i uznanie, że próbka nie pochodzi z rozkładu normalnego.
column = 'Close-Close Returns'
interval = '1quarter interval'
stat, p = stats.normaltest(df_microsoft_quarterly[column])
print(interval + " for " +column + " -> ""p_value: ", p)
W przypadku interwału 3miesięcznego dalej p< 0.05 co oznacza, że musimy odrzucić hipotezę zerową o pochodzeniu próbki z rozkładu normalnego. Na przykładzie tego testu dobrze jest widać, jaki wpływ ma wielkość próbki na test statystyczny. Im większa była próbka tym byliśmy bardziej pewni, że dane nie pochodzą z rozkładu normalnego.
Sprawdźmy teraz co sie stanie po usunięciu wartości odstających:
column = 'Close-Close Returns'
interval = '1day interval'
data = df_microsoft_daily[column]
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
stat, p = stats.normaltest(selected_values)
print(interval + " for " +column + " -> ""p_value: ", p)
column = 'Close-Close Returns'
interval = '1week interval'
data = df_microsoft_weekly[column]
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
stat, p = stats.normaltest(selected_values)
print(interval + " for " +column + " -> ""p_value: ", p)
column = 'Close-Close Returns'
interval = '1month interval'
data = df_microsoft_monthly[column]
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
stat, p = stats.normaltest(selected_values)
print(interval + " for " +column + " -> ""p_value: ", p)
column = 'Close-Close Returns'
interval = '3months interval'
data = df_microsoft_quarterly[column]
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
stat, p = stats.normaltest(selected_values)
print(interval + " for " +column + " -> ""p_value: ", p)
Po odfiltrowaniu wartości odstjacych z danych, zauważamy trend zupełnie odwrotny. Dla interwału dniowego wartość p przyjmuje prawie 1 i jest większe od 0.05 w każdym z interwałów co powoduje, że ne możemy odrzucić hipotezy zerowej o tym, że dane pochodzą z rozkłądu normalnego.
Test Kołmogorowa-Smirnowa
Jest to test nieparametryczny używany do porównywania rozkładów jednowymiarowych cech statystycznych. Istnieją dwie główne wersje tego testu – dla jednej próby i dla dwóch prób. Test dla jednej próby (zwany też testem zgodności λ Kołmogorowa) sprawdza, czy rozkład w populacji dla pewnej zmiennej losowej, różni się od założonego rozkładu teoretycznego, gdy znana jest jedynie pewna skończona liczba obserwacji tej zmiennej (próba statystyczna). Często wykorzystywany jest on w celu sprawdzenia, czy zmienna ma rozkład normalny. Istnieje też wersja testu dla dwóch prób, pozwalająca na porównanie rozkładów dwóch zmiennych losowych. Jego zaletą jest wrażliwość zarówno na różnice w położeniu, jak i w kształcie dystrybuanty empirycznej porównywanych próbek.
$H_{0}$ - dwie próbki pochodzą z rozkładu normalnego $H_{1}$ - próbki nie pochodzą z rozkładu normalnego
Dystrybuanta empiryczna $F_{n}$ dla n-elementowej próby jest zdefiniowana jako funkcja:
$F_{n} = \frac{1}{n}\sum_{i=1}^{n}I_{X_{i}<=x}$
gdzie: $X_{i}$ to wartość zmiennej $X$ dla i-tej obserwacji $I_{X_{i}<=x$ to funkcja charakterystyczna przyjmująca wartość jeden gdy $X_{i}<=x$ i zero w przeciwnym wypadku
Statystyka Kołmogorowa-Smirnowa dla danej dystrybuanty teoretycznej $F(x)$ jest dana wzorem: $D_{n} = sup|F_{n}(x) - F(X)|$
Na mocy twierdzenia Gliwenki-Cantellego, jeśli próba pochodzi z rozkładu o dystrybuancie $F(x)$, to $D_{n}$ dąży prawie wszędzie do zera.
W celu wykonania testu Kołmogorowa-Smirnowa, skorzystamy z dostarczonej wraz z biblioteką scipy funkcji kstest
# Generowanie danych o rozkładzie normalnym i rysowanie wykresu porównawczego
def compare_distribuant(data):
mean = np.mean(data)
std = np.std(data)
df_normal_distribution = np.random.normal(mean, std, len(data))
# Obliczanie histogramów
values, base = np.histogram(data, bins=len(data))
values_norm, base_norm = np.histogram(df_normal_distribution, bins=len(data))
# Obliczanie kumulatywnych sum
cumulative = np.cumsum(values)
cumulative_norm = np.cumsum(values_norm)
# Rysowanie wykresu
fig = plt.figure(figsize=(15, 7.5))
plt.plot(base[:-1], cumulative, c='blue', label='Rzeczywiste dane')
plt.plot(base_norm[:-1], cumulative_norm, c='orangered', label='Dane o rozkładzie normalnym')
# Dodawanie legendy, tytułów i etykiet osi
plt.legend()
plt.title('Porównanie dystrybuant')
plt.xlabel('Wartości')
plt.ylabel('Suma kumulatywna')
# Wyświetlanie wykresu
plt.show()
compare_distribuant(df_microsoft_daily['Close-Close Returns'])

column = 'Close-Close Returns'
interval = '1day interval'
data = df_microsoft_daily[column]
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
def kolmogorow_smirnowa_test(data):
norm = stats.norm
loc, scale = norm.fit(data)
n = norm(loc=loc, scale=scale)
statistic, p_value = stats.kstest(data, n.cdf)
return statistic, p_value
stat, p = kolmogorow_smirnowa_test(df_microsoft_daily[column])
print(interval + " "+column+ " p_value ->" , p)
Po usunięciu wartości odstających:
compare_distribuant(selected_values)

stat, p = kolmogorow_smirnowa_test(selected_values)
print(interval + " "+column+ " p_value ->" , p)
Przed usunięciem wartości odstajacych wynik testu sugeruje nam odrzuecenie hipotezy zerowej, swiadczy to o tym, że dane nie pochodzą z rozkładu normalnego. Po usunięciu wartości odstających widzimy znaczy wzort wskaźnika p która jest o kilkadziesiąt rzędów wielkości większy, natomiast dalej nie pozwala nam to na nie odrzucenie hipotezy zerowej ponieważ p < 0.05.
Te same kroki wykonujemy dla interwałów tygodniowego, miesięcznego i kwartalnego.
Interwał tygoniowy:
Przed usunięciem wartości odstających:
column = 'Close-Close Returns'
interval = '1week interval'
data = df_microsoft_weekly[column]
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
stat, p = kolmogorow_smirnowa_test(df_microsoft_weekly[column])
print(interval + " "+column+ " p_value ->" , p)
compare_distribuant(df_microsoft_weekly[column])

Po usunięciu wartości odstających:
stat, p = kolmogorow_smirnowa_test(selected_values)
print(interval + " "+column+ " p_value ->" , p)
compare_distribuant(selected_values)

Przed usunięciem wartości odstających wynik testu wskazuje na odrzucenie hipotezy zerowej, p = 1.85 * 10^-6 i p< 0.05. Po usunięciu wartości odstających p= 0.27 co jest wieksze od 0.05. To uniemożliwia nam odrzucenie hipotezy zerowej i możemy przyjąć, że dane mogą pochodzic z rozkładu normalnego.
Interwał miesięczny:
Przed usunięciem wartości odstających:
column = 'Close-Close Returns'
interval = '1month interval'
data = df_microsoft_monthly[column]
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
stat, p = kolmogorow_smirnowa_test(df_microsoft_monthly[column])
print(interval + " "+column+ " p_value ->" , p)
compare_distribuant(df_microsoft_monthly[column])

Po usunięciu wartości odstających:
stat, p = kolmogorow_smirnowa_test(selected_values)
print(interval + " "+column+ " p_value ->" , p)
compare_distribuant(selected_values)

Na tym interwale sprawa wygląda podobnie jak na interwale tygodniowym, z tą różnicą, że juz w pierwszym teście bez usunięcia wartości odstających wartość p jest prawie równa 0.05 (0.047), trzymając się jednak zasad musimy odrzucić hipotezę zerową. Po odfiltrowaniu wartości odstających nie mozemy odrzucić hipotezy zerowej: p = 0.15 > 0.05.
Interwał kwartalny
Przed usunięciem wartości odstających:
column = 'Close-Close Returns'
interval = '3months interval'
data = df_microsoft_quarterly[column]
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
stat, p = kolmogorow_smirnowa_test(df_microsoft_quarterly[column])
print(interval + " "+column+ " p_value ->" , p)
compare_distribuant(df_microsoft_quarterly[column])

Po usunięciu wartości odstających:
stat, p = kolmogorow_smirnowa_test(selected_values)
print(interval + " "+column+ " p_value ->" , p)
compare_distribuant(selected_values)

Dla interwału kwartalnego w odydwu przypadkach: przed i po usunięciu wartosci odstających nie możemy odrzucić hopotezy zerowej (p > 0.05), co pozwala nam przypuszczać, żę dane pochodzą z rozkładu normalnego, natomiast nie mamy takiej pewności. Na podstawie tych testów, możemy zauważyć, ze wraz ze spadkiem wielkości próbki zaprzeczenie hipotezie zerowej jest coraz trudniejsze, ponieważ wartość p rośnie.
Test Shapiro-Wilka
Jest standardowym testem wykorzystywanym do testowania normalności danych. Został opublikowany w 1965 roku przez Samuela Shapiro i Martina Wilka. Załóżmy, że pobraliśmy próbę $x_{1},....,x_{n}$ i chcemy sprawdzić czy pochodzi z rozkładu normalnego. Hipoteza zerowa i alternatywna w teście Shapiro–Wilka ma następującą postać: $H_{0}$ - próbka pochodzi z rozkładu normalnego $H_{1}$ - próbka nie pochodzi z rozkładu normalnego
W celu przeprowadzenia testu wykorzystuje się statystykę $W$:
- Uporządkuj obserwacje niemalejąco: $y_{1} <=y_{1} ... <=y_{n} $
- Oblicz: $S^{2} = \sum_{i=1}^{n}(y_{i} - \bar y ) =\sum_{i=1}^{n}(x_{i} - \bar x )$
- Jeżeli n jest parzyste, niech $m = \frac{n}{2}$ w przeciwnym razie $m = \frac{n-1}{2}$
- Używając stabelaryzowanych wartosci $a_{i}$ oblicz $b = \sum_{i=1}^{m}a_{i}(y_{n+1-i} - y_{i})$
- Oblicz statystyke $W = \frac{b^{2}}{S^{2}}$
- Porównaj wynik ze stabelaryzowanymi wartościami dla odpowiednich poziomów ufności i liczebności próby.
Ja natomiast skorzystam z biblioteki scipy, w której test shapiro jest już zaimplementowany. Jeżeli wartośc p bedzie większa od 0.05 to nie będziemy mogli odrzucić hipotezy zerowej $H_{0}$, kiedy jednak p < 0.05 bedziemy mogli uznać, ze próbka nie pochodzi z rozkładu normalnego - $H_{1}$
Pominę interwał jednodniowy, ponieważ dla N>5000 p_value może wyjść błędne, na interwale 1dniowym jest grubo powyżej 5000 rekordów.
Dla danych z wartościami odstającymi:
statistic, p_value = stats.shapiro(df_microsoft_weekly['Close-Close Returns'])
print("1week interval p -> ", p_value)
statistic, p_value = stats.shapiro(df_microsoft_monthly['Close-Close Returns'])
print("1month interval p -> ", p_value)
statistic, p_value = stats.shapiro(df_microsoft_quarterly['Close-Close Returns'])
print("3months interval p -> ", p_value)
Dla danych przefiltrowanych:
column = 'Close-Close Returns'
data = df_microsoft_weekly[column]
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
statistic, p_value = stats.shapiro(selected_values)
print("1week interval p -> ", p_value)
column = 'Close-Close Returns'
data = df_microsoft_monthly[column]
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
statistic, p_value = stats.shapiro(selected_values)
print("1month interval p -> ", p_value)
column = 'Close-Close Returns'
data = df_microsoft_quarterly[column]
Q1 = data.quantile(0.25)
Q3 = data.quantile(0.75)
IQR = Q3 - Q1
left = Q1 - 1.5 * IQR
right = Q3 + 1.5 * IQR
# Wybieramy wartości pomiędzy left a right
selected_values = data[(data >= left) & (data <= right)]
statistic, p_value = stats.shapiro(selected_values)
print("3months interval p -> ", p_value)
Dla danych nieprzefiltrowanych każdy test na każdym interwale nie spełnia warunku p>0.05, więc w każdym z tych przypadków odrzucamy hipotezę zerową. Dla danych przefiltorwanych kryterium p>0.05 spełnia tylko interwał 3miesięczny. Nie możemy odrzucić hipotezy, że dane pochodzą z rozkładu normalnego
Badanie korelacji zmiennych
Korelacja Pearsona Zobaczmy, korzystając z macierzy korelacji, między którymi parami zmiennych istnieje najsilniejsza zależność. W tym przypadku skorzystamy ze współczynnika korelacji Pearsona, który mierzy liniową zależność między parą zmiennych.
Dla interwału 1dniowego:
new_df = df_microsoft_daily[[ 'Close-Close Returns', 'High-Low Returns', 'Open-Close Returns', 'Volume']]
figure = plt.figure(figsize=(15, 7.5))
g = sns.heatmap(new_df.corr('pearson'), cmap="BuGn", vmax=1, vmin=-1, center=0, annot=True)
g.set_xticklabels(g.get_xticklabels(), rotation=45, horizontalalignment='right')
plt.show()

Dla interwału 1tygodniowego:
new_df = df_microsoft_weekly[[ 'Close-Close Returns', 'High-Low Returns', 'Volume']]
figure = plt.figure(figsize=(15, 7.5))
g = sns.heatmap(new_df.corr('pearson'), cmap="BuGn", vmax=1, vmin=-1, center=0, annot=True)
g.set_xticklabels(g.get_xticklabels(), rotation=45, horizontalalignment='right')
plt.show()

DLa interwału 1miesięcznego:
new_df = df_microsoft_monthly[[ 'Close-Close Returns', 'High-Low Returns', 'Volume']]
figure = plt.figure(figsize=(15, 7.5))
g = sns.heatmap(new_df.corr('pearson'), cmap="BuGn", vmax=1, vmin=-1, center=0, annot=True)
g.set_xticklabels(g.get_xticklabels(), rotation=45, horizontalalignment='right')
plt.show()

Dla interwału 3miesięcznnego:
new_df = df_microsoft_quarterly[[ 'Close-Close Returns', 'High-Low Returns', 'Volume']]
figure = plt.figure(figsize=(15, 7.5))
g = sns.heatmap(new_df.corr('pearson'), cmap="BuGn", vmax=1, vmin=-1, center=0, annot=True)
g.set_xticklabels(g.get_xticklabels(), rotation=45, horizontalalignment='right')
plt.show()

Dla wszystkichczterech interwałów, widać korelacje tylko dla kolumn: Volume i High-Low Returns, reszta zmiennych nie wykazuje ze sobą praktycznie żadnej korelacji. Wartość w okolicach 0.50 wskazuje, że istnieje umiarkowana dodatnia korelacja między badanymi zmiennymi. Oznacza to, że zmienne te zmieniają się razem w pewien sposób, ale nie jest to związane z bardzo silną zależnością. Przypomnijmy co oznaczają zmienne Volume i High-Low Returns:
High - najwyższa cena instrumentu finansowego osiągnięta w trakcie danego okresu czasu (np. jednej sesji handlowej). To jest największa wartość, którą osiągnęła cena w danym przedziale czasowym.
Low - najniższa cena instrumentu finansowego osiągnięta w trakcie danego okresu czasu. To jest najmniejsza wartość, którą osiągnęła cena w danym przedziale czasowym.
Volume - wolumen to liczba jednostek instrumentu finansowego, które zostały wymienione w danym okresie czasu. Oznacza to, ile razy dany instrument finansowy został kupiony lub sprzedany w danym przedziale czasowym.
High-to-Low Returns [daily, weekly, monthly quarterly data] $Formula = \frac{High_{ period [x]} - Low_{period [x]}}{Low_ {period [x]}} $
Korelacja pomiedzy High-Low Returns a Volume nie jest niespodziewana, ponieważ cena reaguje na ilość kupionych jednostek instrumentu finansowego w jednostce czasu co przekłada sie na skoki ceny instrumentu a te skoki ceny w danym interwale reprezentuje High-Low Returns.
Do rysowania pomocniczych wykresów, w tym wykresy z dopasowną prostą posłużę się funkcjami poniżej. Ze względu na ilość danych dla interwału 1dniowego użyję wykresu kernel density. Funkcja trim_data usuwa wartości odstające, używam jej ponieważ wykres z wartościami odstającymi byłby nieczytelny.
def reg_plot(data, x_col, y_col):
g = sns.lmplot(x=x_col, y=y_col, data=data, fit_reg=False)
sns.regplot(x=x_col, y=y_col, data=data, scatter=False, ax=g.axes[0, 0])
g.fig.set_figwidth(15)
g.fig.set_figheight(7.5)
def reg_plot_hexbin(data, x_col, y_col):
g = sns.jointplot(x=x_col, y=y_col, data=data, kind='hex', cmap='Blues')
g.fig.set_figwidth(15)
g.fig.set_figheight(7.5)
def reg_plot_krenel_density(data, x_col, y_col):
g = sns.jointplot(x=x_col, y=y_col, data=data, kind='kde', cmap='Blues')
g.fig.set_figwidth(15)
g.fig.set_figheight(7.5)
def trim_data(data):
Q1 = data['High-Low Returns'].quantile(.25)
Q3 = data['High-Low Returns'].quantile(.75)
IQR = Q3 - Q1
left = Q1 - 1.5*IQR
right = Q3 + 1.5*IQR
data = data[(data['High-Low Returns'] >=left ) & (data['High-Low Returns'] < right)]
Q1 = data['Volume'].quantile(.25)
Q3 = data['Volume'].quantile(.75)
IQR = Q3 - Q1
left = Q1 - 1.5*IQR
right = Q3 + 1.5*IQR
data = data[(data['Volume'] >=left ) & (data['Volume'] < right)]
return data
Interwał jednodniowy:
data = trim_data(df_microsoft_daily)
reg_plot_krenel_density(data,'High-Low Returns','Volume')

Interwał tygodniowy:
data = trim_data(df_microsoft_weekly)
reg_plot(data.sample(200),'High-Low Returns','Volume')

Interwał miesięczny:
data = trim_data(df_microsoft_monthly)
reg_plot(data.sample(200),'High-Low Returns','Volume')

Interwał kwartalny:
data = trim_data(df_microsoft_quarterly)
reg_plot(data,'High-Low Returns','Volume')

Na przedstawionymch wykreach widzimy dodatnia korelację zmiennych High-Low Retuns i Volume. Wizualnie wydaje się, że wraz ze wzrostem interwału, punkty wydają się być bardziej zbliżone do narysowanej prostej regresji. W dalszej części bedę badał jak dobre jest to dopasowanie prostej i będę takżę próbował osacować stopień wielomianu, który najlepiej dopasowywuje sie do danych.
Do obliczania współczynnika determinacji $R^2$ wykorzystam poniższe funkcje które korzystają z biblioteki scikit-learn. Wartości $R^2$2 bliskie 1 oznaczają wysoki poziom dopasowania, natomiast wielkości bliskie 0 oznaczają słabe dopasowanie.
def coefficient_of_determination_linear(df, col_x, col_y):
x = np.array(df[col_x]).reshape((-1, 1))
y = df[col_y]
model = linreg().fit(x, y)
return model.score(x, y)
def coefficient_of_determination_polynomial(df, x_col, y_col, degree):
x = np.array(df[x_col]).reshape((-1, 1))
y = df[y_col]
transformer = polyfeat(degree=degree, include_bias=False)
transformed_x = polyfeat(degree=degree, include_bias=False).fit_transform(x)
model = linreg().fit(transformed_x, y)
return model.score(transformed_x, y)
def print_score(score):
print("R^2 score -> " + str(score))
Interwał jednodniowy:
print_score(coefficient_of_determination_linear(df_microsoft_daily,'High-Low Returns','Volume'))
print_score(coefficient_of_determination_polynomial(df_microsoft_daily,'High-Low Returns','Volume',10))
Najlepsze dopsanowanie uzyskałem, dla wielomianu 10 stopnia.
Interwał tygodniowy:
print_score(coefficient_of_determination_linear(df_microsoft_weekly,'High-Low Returns','Volume'))
print_score(coefficient_of_determination_polynomial(df_microsoft_weekly,'High-Low Returns','Volume',8))
Najlepsze dopasowanie uzyskałem dla wielomianu stopnia 8.
Interwał miesięczny
print_score(coefficient_of_determination_linear(df_microsoft_monthly,'High-Low Returns','Volume'))
print_score(coefficient_of_determination_polynomial(df_microsoft_monthly,'High-Low Returns','Volume',7))
Najlepsze dopasowanie uzyskałem dla wielomianu 7 stopnia.
Interwał kwartalny
print_score(coefficient_of_determination_linear(df_microsoft_quarterly,'High-Low Returns','Volume'))
print_score(coefficient_of_determination_polynomial(df_microsoft_quarterly,'High-Low Returns','Volume',7))
Największe dopasowanie uzyskałem dla wielomian u stopnia 7.
Obliczone statystyki $R^2$ dla dopasowanych prostych do wykresu wskazują na bardzo słabe dopasowanie tychże prostych. Największym współczynnikiem determinacji wykazuje sie prosta dopoasowana na wykresie interwału tygodniowego. Dla niej współczynnik determinacji wynosi 0.374. Jest to niewielka przewaga względem pozostałych dopasowań dla innych interwałów, wszystkie oscylują wokół 0.3 co jest raczej słąbym współczynnikiem determinacji
Dopasowanie krzywej wielomianowej wygląda podobnie. Wartości współczynnika determinacji także oscylują wokół 0.35, a najlepszym dopasowanie należy do interwału tygodniowego, podobnie jak w przypadku dopasowania prostej tutaj ten współczcynnik jest największy ale dalej mizerny. Stwierdzam, że nie da sie dopasować prostych/krzywych wielomianowych do zmiennych z dużą dokładnością co jest spowodowane słabym współczynnikiem korelacji pomiedzy zmiennymi High-Low Retuns a Volume, który jest na poziomie około 0.5.
Podsumowanie i wnioski
Wartości odstające w każdym z interwału dla każdej obliczonej kolumny oscylują w okolicach 5% wszystkich danych i maja istotny wpływ na, późniejsze cechy rozkładu zmiennych. Wartość średnia maleje wraz ze wzrostem interwału. Dla interwału 1dniowego oscyluje w okolichac zera, natomiast z podnoszeniem interwału znajduje się coraz bardziej poniżej zera. Za sprawa ciągłego zmniejszania się wartości średniej zwrotu Close-Close Returns, zwiększa się procentowy udział negatywtnych zwrotów, który dla interwału kwartalnego wynosi, aż 66% wszystkich wartości.
Rozkład zmiennej Close-Close Returns dla każdego interwału jest prawostronnie skośny i leptokurtyczny. Wraz ze wzrostem interwału maleje skośność prawostronna i wskaźnik wyostrzenia. Wskaźnik wyostrzenia maleje gwałtownie z poziomu 24 do okolic zera dla interwału kwartalnego.
Głównym wnioskiem z przeprowadzonych testów statystycznych jest to, że surowe dane, które zawierają wartości odstające nie pozwalają na stwierdzenie, że nie pochodzą one z rozkładu normalnego. Po usunięciu wartości odstających bład pierwszego rodzaju mówiący o prawdopodobieństwie błedu przy odrzuceniu hipotezy zerowej (hipoteza zerowa w większości zakładała, ze dane pochodzą z rozkładu normalnego) rośnie dla coraz to większysch interwałów. Rośnie m.in. dla tego, że zmiejsza sie siłą rzczy testowana próbka.
Jakąkolwiek korelacje możemy zaobserwować dla zmiennych losowych Volume i High-Low Returns, która to to wynosi około 0.5, najwiecej dla interwału tygodniowego - 0.6. Dla reszty zmiennych nie obserwujemy praktycznie żadnej korelacji - korelacja dla pozostałych oscyluje wokół zera. Umiarkowana korelacja nie pozwala na dokładne dopasowanie zarówno prostych jak i wielominanów różnego stopnia. Współczynnik determinacji w każdym z przypadków oscyluje w okolicach 0.30 - 0.35 co jest słabym dopasowaniem prostej/wielomianu do zmiennych.